It is not as easy as you think. And let me explain why?
There are so many misconceptions about the SRE = DevOps. But, it is NOT equal and there are so many things in SRE that DevOps won’t cover. For example, DevOps focus more on Deployment Velocity and application uptime. But, SRE focus on SILOs and Error budgets. DevOps won’t take any authority on deployments nor it influences the deployment velocity. Where SRE can STOP Deploying the application when the Error budget is exceeded. So, this proves SRE has authority in the SDLC process and also it can impact the business owner’s view.
And There is say “SRE Class Implement DevOps”. if we take SRE as one Big function….
SRE(DevOps) {
ci();
cd();
mon();
testing();
....
}I would assume that most Organizations are practicing the DevOps that want to jump into SRE to increase their Application or Product uptime and focus on the SILOs.
DevOps to SRE
1. There are not many changes required, easy to get started on your SRE journey. DevOps is mainly focused CI/CD, automation, and monitoring apps. with this DevOps team easily adapt the SRE culture by Implementing the additional controls in SRE. This is still a big change but i would say that should be the start.
2. You can practice and adopt SRE approach, an experiment in your environment (product) at a low cost. As i mentioned above, we can start with the DevOps controls, and moving forward the Practicing the SRE controls won’t cost.
3. FullStack to SRE Journey. Small and medium enterprise Companies have a limited # of DevOps Engineers following the full-stack engineering model. -That case implemented SRE will be 5 Steps Process.
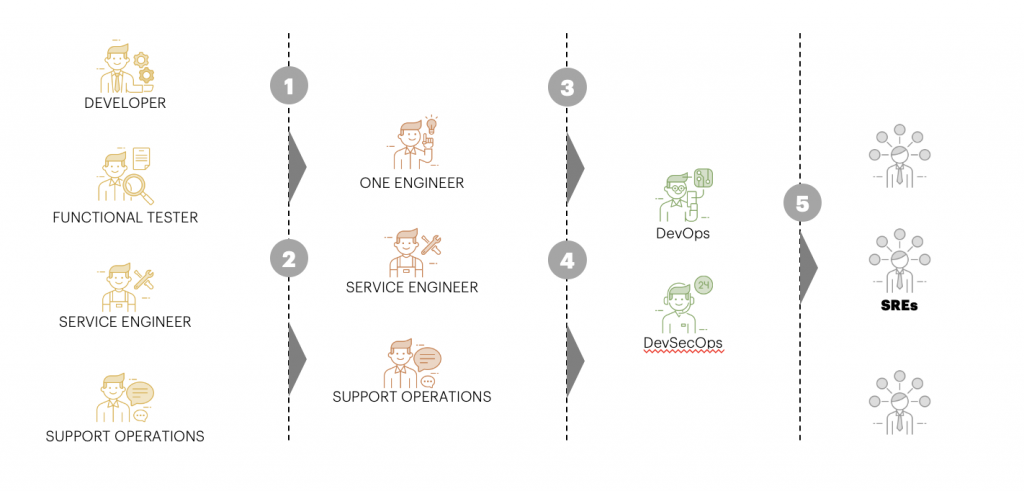
4. No knowledge/coverage gaps between SRE/DevOps teams. DevOps acts as a glue between various teams that are creating solutions, dependent on each other, or consists out of distinct pieces of software. So, moving to SRE from DevOps is not going to be challenging.
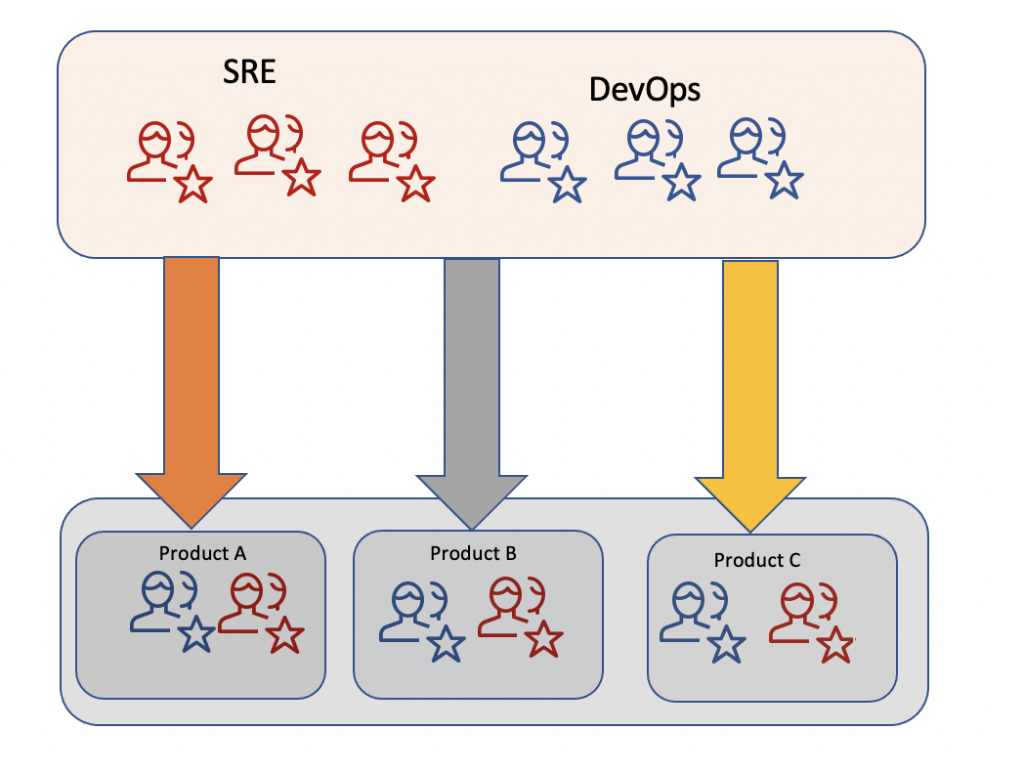
Again, this transformation depends on how teams collaborate with each other and how fast they can adapt to the change. There are a few Good books available for you to learn SRE Approach. But in my view, not all textbooks and theories can teach you with specific teams structure that you have. Understanding the current state is the starting point for the SRE journey.
Here Some of SRE books links:
Site Reliability Engineering: How Google Runs Production Systems (known as “The SRE Book”)
The Site Reliability Workbook: Practical Ways to Implement SRE (known as “The SRE Workbook”)
Seeking SRE: Conversations About Running Production Systems at Scale
Let me know your thoughts in comments.
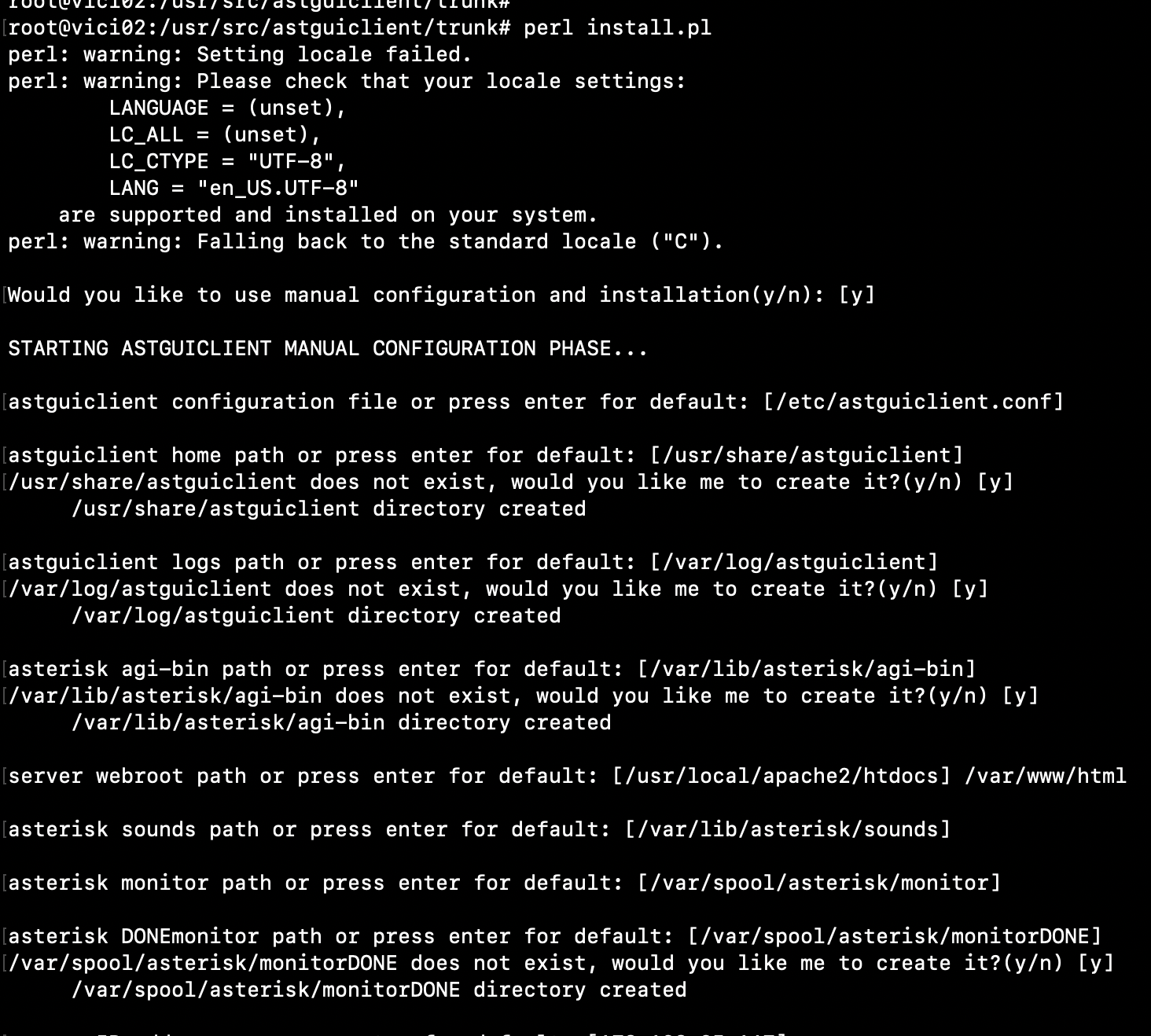 #Configiguration example
#Configiguration example
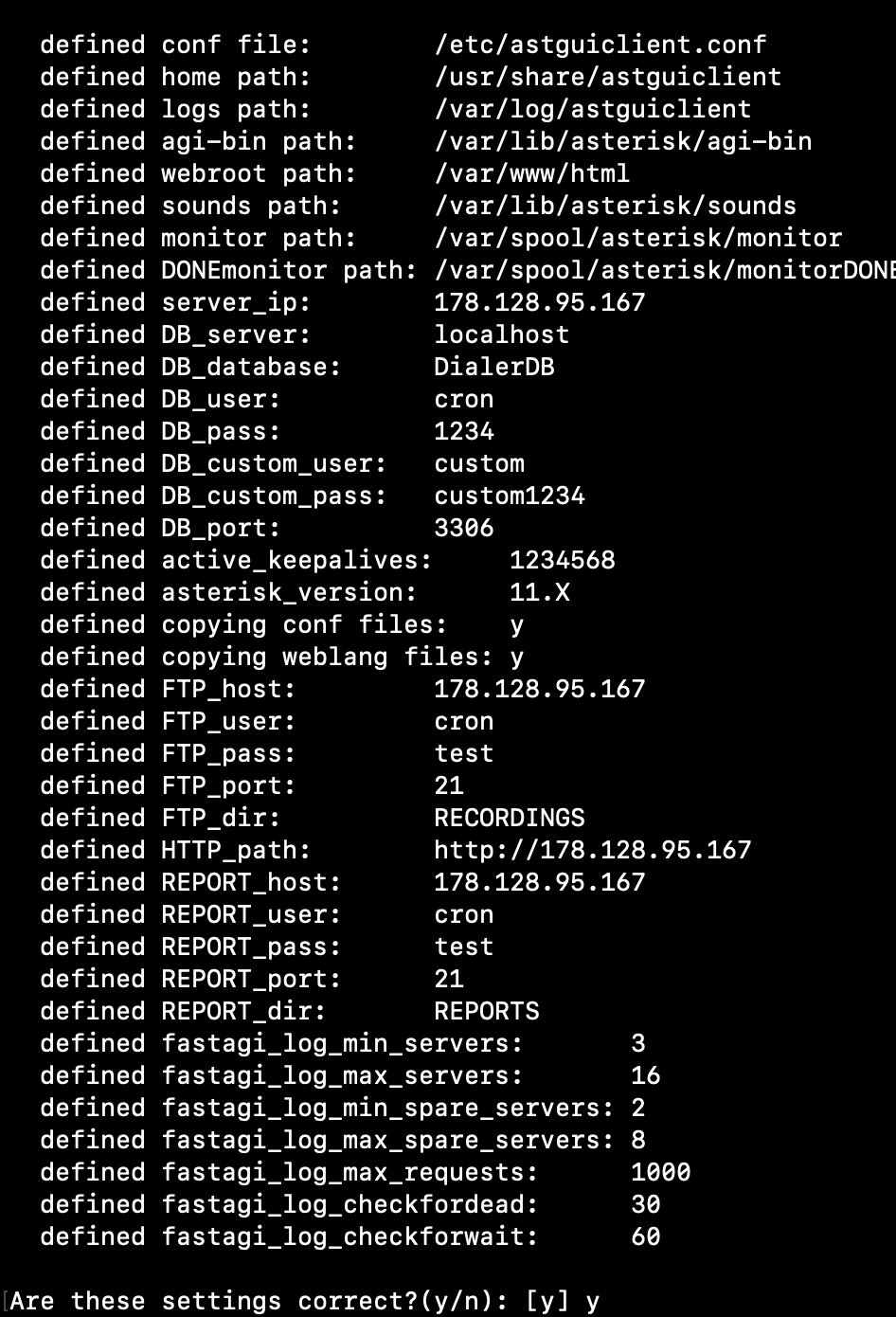 #Populate ISO country codes
cd /usr/src/astguiclient/trunk/bin perl ADMIN_area_code_populate.pl
#update the Server IP with latest IP address.(VICIDIAL DEFAULT IP IS 10.10.10.15)
perl /usr/src/astguiclient/trunk/bin/ADMIN_update_server_ip.pl --old-server_ip=10.10.10.15 #Say 'Yes' to all
#Populate ISO country codes
cd /usr/src/astguiclient/trunk/bin perl ADMIN_area_code_populate.pl
#update the Server IP with latest IP address.(VICIDIAL DEFAULT IP IS 10.10.10.15)
perl /usr/src/astguiclient/trunk/bin/ADMIN_update_server_ip.pl --old-server_ip=10.10.10.15 #Say 'Yes' to all